
Cómo los modelos fundacionales están cambiando la forma en que analizamos datos geoespaciales, y por qué ArcGIS Pro 3.7 acaba de poner ese paradigma a un par de clics de distancia.
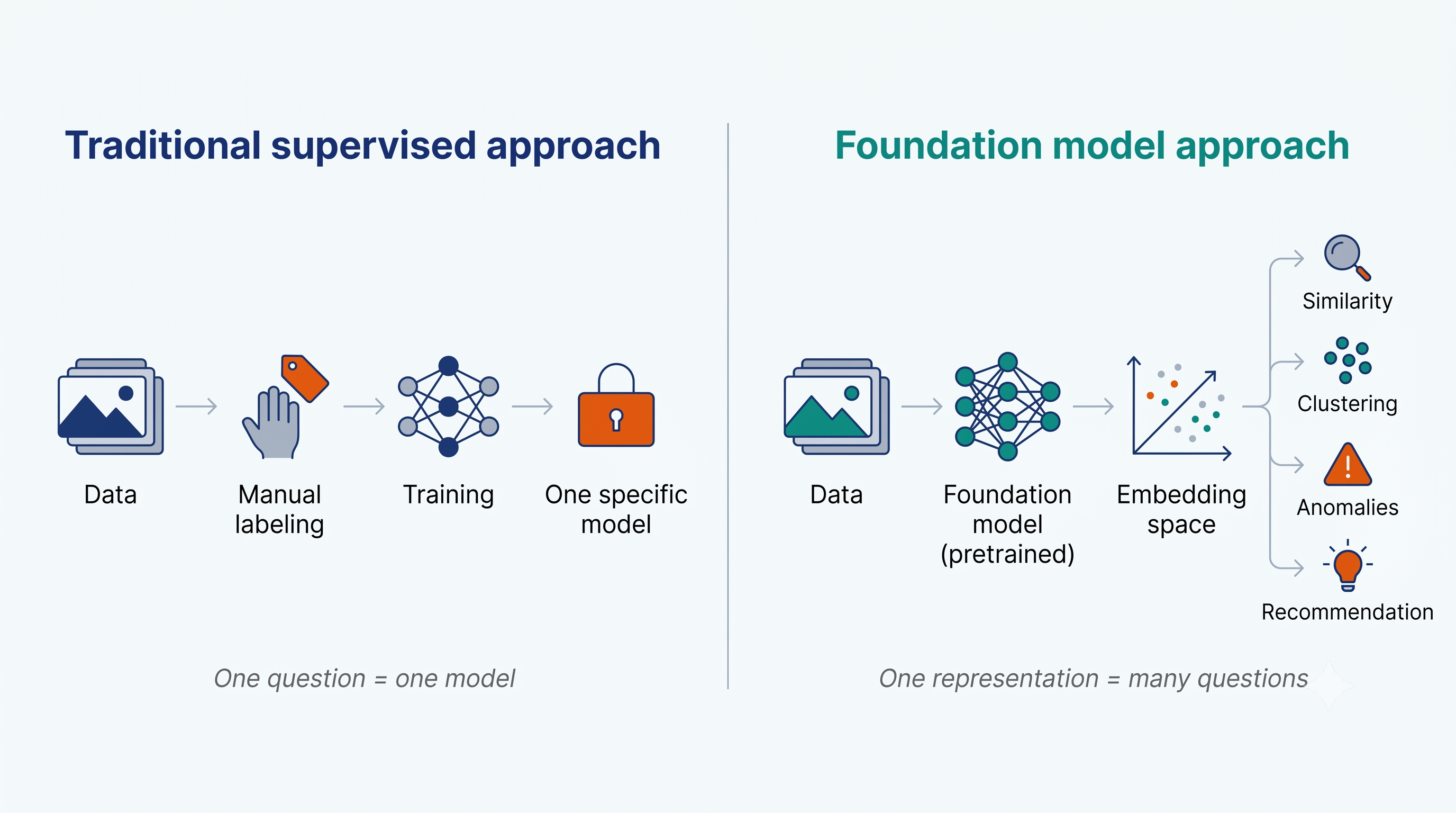
Durante años, hacer analítica avanzada sobre datos geoespaciales tuvo un techo invisible. Si no podías cuantificar bien algo, no podías analizarlo. Querías saber qué predios se parecen entre sí en una ciudad. Querías ver qué tramos de una red tienen un comportamiento atípico. Querías encontrar zonas urbanas que siguen un patrón similar a otra ya intervenida. Y la respuesta casi siempre era la misma: entrenar un modelo dedicado para esa pregunta específica. Datos etiquetados, GPU, semanas de trabajo, y un modelo que terminaba sirviendo para una sola cosa.
Los embeddings rompen ese techo. No son una técnica más dentro del catálogo de machine learning. Son una forma distinta de representar la realidad, y una vez la información está representada así, se abren puertas analíticas que antes costaban un proyecto entero.
En este post voy a entrar al detalle. Qué es un embedding, qué es un modelo fundacional, cómo se conectan los dos en el video que comparto más adelante, y qué se puede hacer con ellos dentro de ArcGIS Pro 3.7. Lo escribí pensando en analistas y profesionales GIS que quieren entender el paradigma de fondo, no solo verlo funcionar.
1. ¿Qué es un embedding?
Un embedding es un vector de números que representa algo (una imagen, un predio, un texto, un nodo de una red) como un punto en un espacio matemático de muchas dimensiones.
La idea de fondo es esta: ese espacio se construye de tal forma que la cercanía geométrica entre dos puntos significa parecido en el mundo real. Dos imágenes visualmente similares quedan cerca. Dos predios con perfil parecido quedan cerca. Dos denuncias ciudadanas que describen el mismo problema en palabras distintas también quedan cerca.
La distancia es la información. Esa es la frase que vale la pena retener.
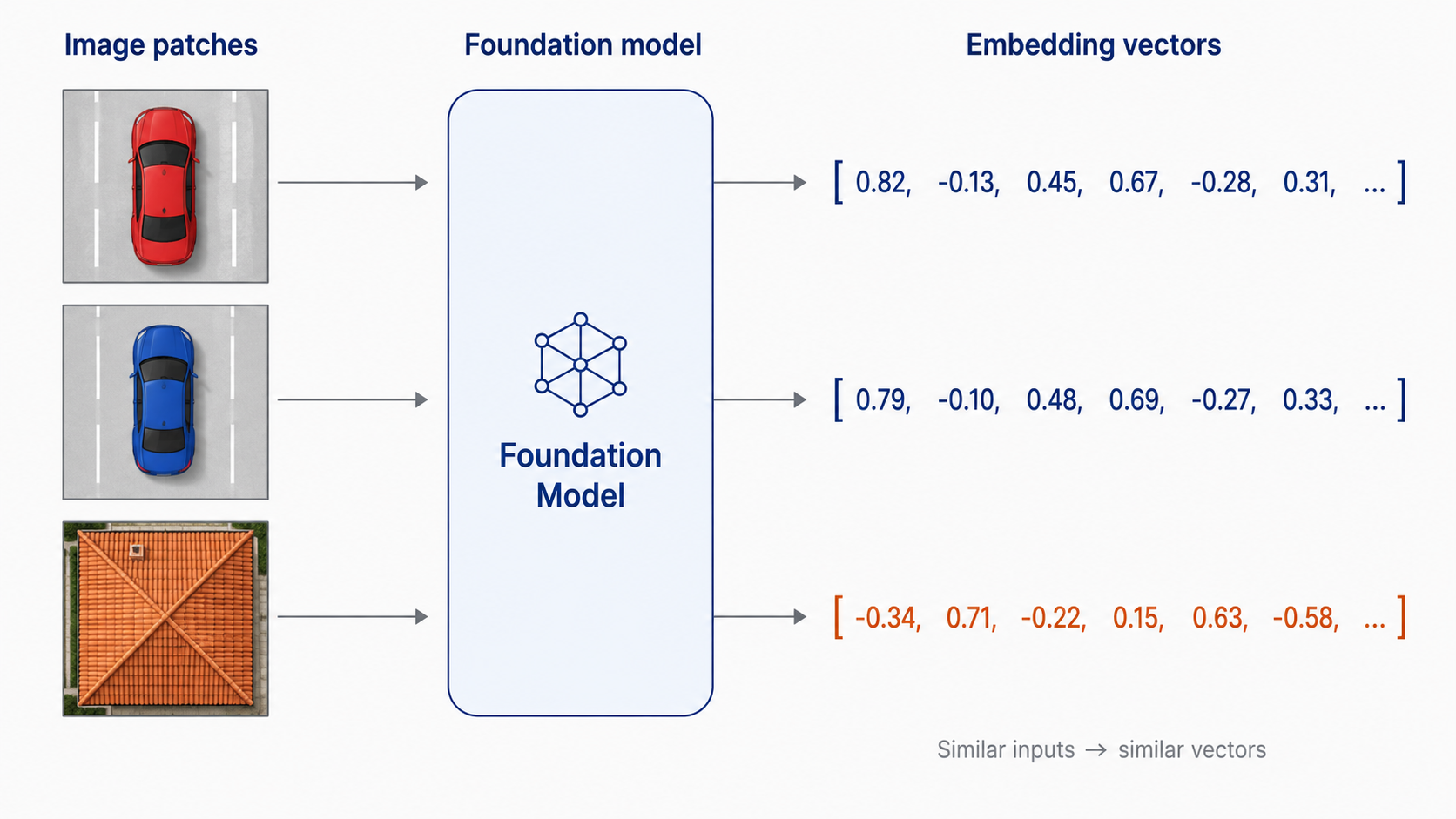
Un ejemplo concreto. Si pasamos tres parches de una ortofoto por un modelo de embeddings, podríamos obtener algo así (simplificado a tres dimensiones para que sea legible, en la práctica son cientos o miles):
Carro rojo en parqueadero → [0.82, -0.13, 0.45, ...]
Carro azul en calle → [0.79, -0.10, 0.48, ...]
Techo de teja → [-0.34, 0.71, -0.22, ...]
Los dos vectores de carros son casi idénticos a pesar de que uno es rojo y otro azul, está en una posición distinta y tiene un fondo diferente. El del techo es completamente distinto. El modelo aprendió a capturar la estructura visual que hace que dos cosas sean del mismo tipo, ignorando lo accesorio.
Cuando uno mide cuán cerca están dos embeddings (normalmente con distancia coseno o euclidiana), está midiendo cuán parecidos son los originales. Ese es el truco completo. Lo demás son consecuencias.
Una analogía útil
Un embedding es a una imagen lo que las coordenadas son a un lugar. Una ciudad no es un par de números, pero asignarle latitud y longitud nos permite calcular distancias, encontrar lo más cercano, agrupar zonas. Las coordenadas no son la ciudad. Son una representación que habilita análisis.
Los embeddings hacen lo mismo, pero en lugar de dos dimensiones geográficas son cientos de dimensiones semánticas. Y en lugar de capturar dónde está algo, capturan qué es.
2. ¿Quién aprende a generar esos vectores? Los modelos fundacionales
Lo que hace posible que un vector capture el parecido entre dos cosas es el modelo que lo genera. Y aquí entra el segundo concepto clave: los modelos fundacionales.
Un modelo fundacional es un modelo de deep learning entrenado a gran escala (cientos de millones de ejemplos, muchas veces miles) sin una tarea específica en mente. No le enseñas a reconocer carros, ni a clasificar predios, ni a detectar deforestación. Le pides algo más general: que aprenda a representar la estructura del mundo dentro de un dominio (imágenes, texto, datos tabulares).
Para entender la diferencia con el paradigma anterior, vale la pena el contraste:
Modelos supervisados tradicionales (lo que veníamos haciendo):
- Una tarea por modelo.
- Requieren etiquetado manual masivo.
- El conocimiento queda encerrado en una pregunta específica.
- Cambiar la pregunta significa volver a entrenar.
Modelos fundacionales:
- Una representación general, reutilizable.
- Entrenamiento self-supervised (el modelo se inventa sus propias tareas con datos no etiquetados).
- El conocimiento queda en una representación que sirve para muchas preguntas.
- Cambiar la pregunta es cambiar la consulta sobre el espacio, no reentrenar.
El modelo que uso en el video es DINOv2, publicado por Meta AI Research. Es un modelo fundacional para imágenes, entrenado con 142 millones de imágenes sin etiquetar usando una técnica llamada self-distillation. No sabe qué es un carro, ni un árbol, ni un techo. Sabe representar imágenes.
Y es open source. Corre local, sin enviar nada a la nube. Esa última frase importa más de lo que parece. Para clientes en gobierno, defensa, banca o infraestructura crítica, "los datos no salen de la red" deja de ser una restricción operativa y se vuelve una garantía que se puede comunicar.
3. El video: cómo se ve esto dentro de ArcGIS Pro 3.7
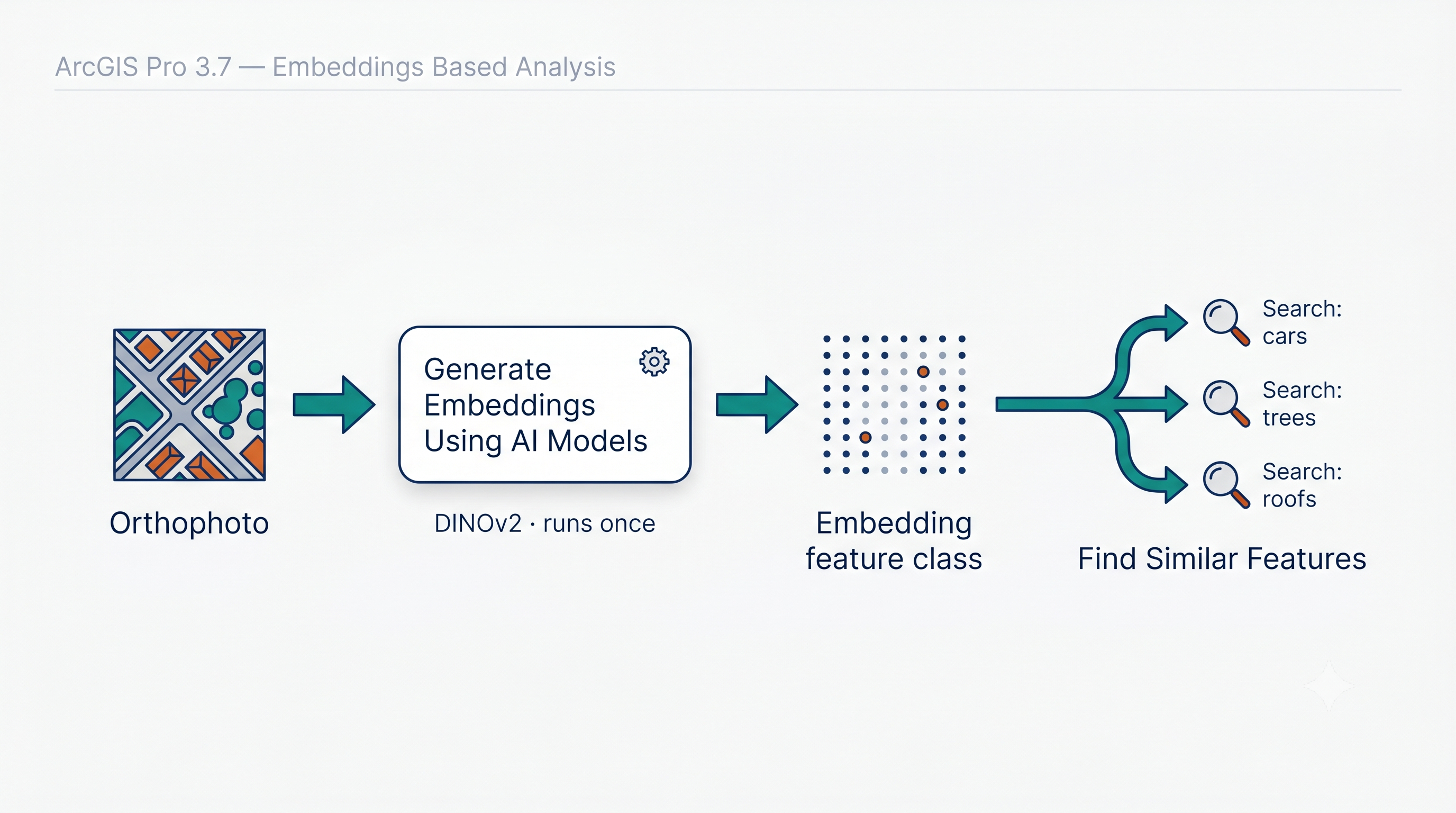
ArcGIS Pro 3.7 introdujo en su GeoAI toolbox un toolset llamado Embeddings Based Analysis, con cuatro herramientas: Generate Embeddings Using AI Models, Find Similar Features Using Embeddings, Merge Embeddings y Extract Embeddings To Fields. Para este post nos interesan las dos primeras, que son las que aparecen en el video.
El flujo del video es simple a propósito.
Paso 1: generar los embeddings
Le paso a la herramienta Generate Embeddings Using AI Models una ortofoto de alta resolución, capturada con dron sobre un barrio de Bogotá. Como modelo, DINOv2 empaquetado en un .dlpk. La herramienta divide la ortofoto en parches pequeños y, para cada uno, calcula un vector de embedding usando el modelo.
El resultado no es una imagen. Es una feature class donde cada feature representa un parche de la imagen original y lleva su vector de embedding asociado en un campo binario.
Este paso toma alrededor de 10 segundos en mi instalación local. Es el único paso costoso del flujo, y se hace una sola vez. Todo lo que viene después consulta esa representación; el modelo no se vuelve a tocar.
Paso 2: hacer preguntas sobre el espacio
Con la capa de embeddings generada, abro el panel Find Similar. Selecciono uno o dos parches como referencia, y la herramienta calcula la similitud entre el embedding promedio de mis referencias y el embedding de todos los demás parches de la imagen. Los más similares se devuelven como selección.
En el video hago tres búsquedas consecutivas:
- Carro como referencia. El sistema marca 107 vehículos en toda la ortofoto.
- Árbol como referencia. Marca la vegetación.
- Construcción como referencia. Marca los techos.
Mismo modelo. Misma capa de embeddings generada en el paso 1. Tres preguntas radicalmente distintas, ninguna anticipada en el entrenamiento del modelo.
Lo que estamos haciendo en cada búsqueda, técnicamente, es un nearest neighbor search en el espacio vectorial: encontrar los puntos más cercanos a un punto de consulta. Eso es todo. La complejidad analítica se mudó del entrenamiento a la representación, y la consulta es trivial.

Sobre el umbral
Find Similar expone un parámetro de threshold (en mi caso, 0.50). Ese número controla qué tan estricta es la búsqueda, qué tan cerca tiene que estar un parche del embedding de referencia para ser incluido. Subirlo recupera menos resultados pero más precisos; bajarlo recupera más cobertura a costa de falsos positivos. Es la única perilla que hay que afinar en este flujo, y es una decisión analítica, no un hiperparámetro de modelo.
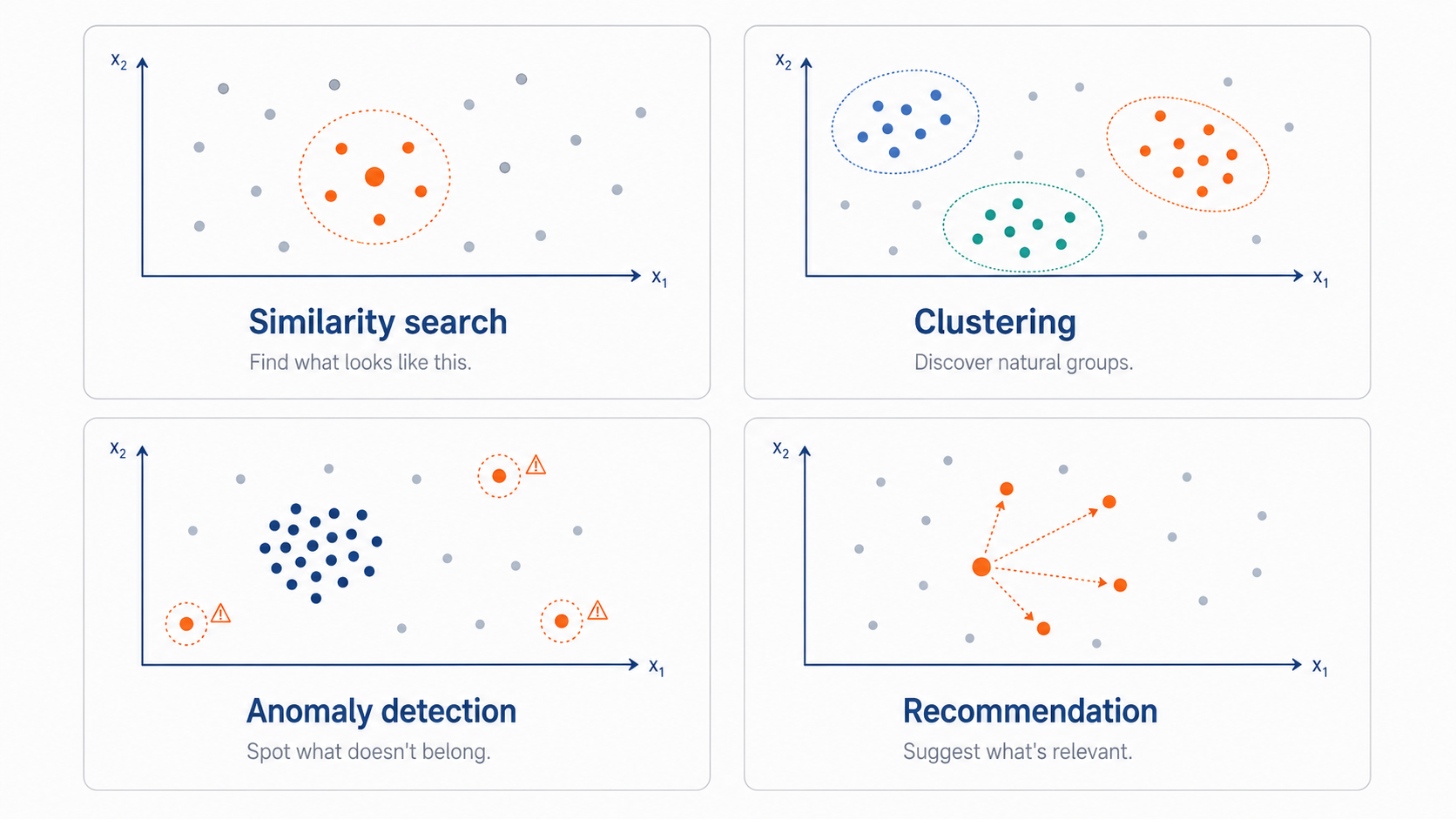
4. Las cuatro puertas que abre el espacio vectorial
Una vez tu información está representada en un espacio de embeddings, hay cuatro familias de análisis que se vuelven baratas. Las cuatro se reducen a operaciones geométricas sobre el espacio.
Búsqueda por similitud
Lo que muestra el video. Dado un punto de referencia, encontrar sus vecinos más cercanos. Operacionalmente, nearest neighbor search con distancia coseno o euclidiana.
Aplicaciones GIS: detección automática de features parecidos en imágenes, búsqueda de predios con perfil similar para valoración masiva, identificación de expedientes catastrales con patrones recurrentes, recuperación de documentos territoriales por contenido.
Agrupamiento (clustering)
Encontrar grupos naturales de puntos en el espacio. Algoritmos clásicos como k-means, DBSCAN o HDBSCAN aplicados directamente sobre los embeddings.
Aplicaciones GIS: segmentación de zonas urbanas con patrón similar, tipificación automática de cubiertas a partir de imagen, agrupamiento de denuncias ciudadanas por tema sin definir las categorías a priori.
Detección de anomalías
Identificar puntos que están lejos de cualquier cúmulo en el espacio. Distancia al vecino más cercano, métodos de densidad, isolation forest sobre los embeddings.
Aplicaciones GIS: tramos de red con comportamiento atípico, parcelas con declaración inconsistente con su entorno, infraestructuras dañadas tras un evento climático, construcciones que no encajan con el patrón del barrio.
Recomendación
Dado un conjunto de elementos de interés del usuario, sugerir otros parecidos. La columna vertebral de los recomendadores modernos.
Aplicaciones GIS: "predios candidatos para inspección dado este patrón", "zonas con perfil similar a esta intervención exitosa", sugerencia de capas relevantes en un portal a partir del contenido que ya consume un usuario.
5. No es solo imágenes, y aquí está lo importante
El video muestra el caso visual porque es el más fácil de ver. Pero el toolset de ArcGIS Pro 3.7 acepta tres tipos de entrada en Generate Embeddings Using AI Models:
- Imágenes (rásteres), el caso del video, con modelos como DINOv2.
- Features geográficas con sus atributos: predios, polígonos, puntos con su tabla de atributos asociada.
- Atributos de texto: campos de descripción, narrativas, denuncias, observaciones de campo.
Una vez cualquiera de los tres está convertido en embeddings, vive en un espacio vectorial. Y un espacio vectorial es indiferente al tipo de dato que generó los vectores. Las mismas cuatro puertas analíticas se abren igual.
Esto es lo que el video no alcanza a mostrar y que vale la pena nombrar:
- Un conjunto de predios representado como embeddings permite encontrar parcelas con perfil parecido para valoración por comparación masiva.
- Un corpus de expedientes catastrales o denuncias ciudadanas en texto permite agrupar quejas por tema real, no por categoría declarada.
- Una capa de polígonos urbanos con sus atributos puede compararse con otra capa intervenida para encontrar zonas candidatas a la misma política.
Una nota de honestidad técnica: la madurez del paradigma no es la misma en todos los casos. Los modelos fundacionales de imagen (DINOv2, CLIP) y de texto (familias de BERT, modelos de embeddings de OpenAI o Cohere) son muy robustos. Los modelos fundacionales para datos tabulares geoespaciales son más jóvenes. Esri ha avanzado fuerte con su Geo-Demographic Foundation Model, presentado en el Developer Summit 2026, y otros vienen en camino. La promesa del paradigma es la misma para los tres casos; la disponibilidad de modelos pretrained varía.
6. ¿Por qué esto importa para el trabajo GIS en LATAM?
Hay tres cosas que cambian, de fondo, cuando un equipo GIS adopta este paradigma.
Primero, la economía del análisis cambia. El costo grande se paga una vez, al generar los embeddings, y muchas preguntas se vuelven baratas sobre la misma representación. Análisis que antes no entraban en el presupuesto vuelven a ser viables.
Segundo, lo cualitativo entra al modelo. Características de un barrio, similitudes visuales, parecidos entre textos, patrones difíciles de describir en columnas. Todo eso pasa de ser "demasiado cualitativo para analizar" a ser una distancia más en el espacio.
Y tercero, la barrera de entrada baja. No hay que entrenar nada. No hay que etiquetar nada. El analista vuelve a estar donde debería estar: haciendo preguntas inteligentes sobre la realidad, no construyendo pipelines de entrenamiento.
Para la región eso es particularmente relevante. Buena parte del análisis territorial sofisticado no se hacía porque los equipos no tenían capacidad de entrenar modelos propios. Esa restricción acaba de cambiar.
7. Cómo empezar
Si quieres experimentar con esto en tu instalación, el camino es directo:
- Actualiza a ArcGIS Pro 3.7 y verifica que tengas instalados los Deep Learning Libraries de la versión correspondiente.
- Descarga un modelo fundacional empaquetado como
.dlpkdesde Living Atlas o desde tu propia conversión de DINOv2. - Prueba
Generate Embeddings Using AI Modelssobre una imagen pequeña primero. Un recorte de 1 a 2 km² es suficiente para tantear tiempos. - Abre el panel
Find Similary juega con el threshold. Esa es la mejor forma de internalizar la idea de "cercanía = parecido". - Una vez cómodo con imágenes, prueba con un feature class con atributos de texto. El cambio mental es importante: te convences de que el paradigma es general, no visual.
Lo que se queda conmigo
Los embeddings no son una mejora incremental. Son un cambio en la forma de representar la información geoespacial, y por lo tanto en las preguntas que podemos hacerle.
Lo que un modelo supervisado tradicional resolvía con meses de trabajo y un caso de uso específico, un modelo fundacional lo deja accesible como una consulta sobre un espacio. La parte cara se hace una vez. Las preguntas se vuelven intercambiables.
Si llevan años con análisis en el cajón porque "no daba para entrenar un modelo dedicado", esta es la herramienta para volver a ponerlos sobre la mesa.
Si te interesan estos temas, en GeoAI LATAM estamos construyendo comunidad alrededor de la inteligencia artificial aplicada a datos geoespaciales en español, combinando herramientas abiertas (Python, GDAL, QGIS) y comerciales (ArcGIS). Te invito a la conversación.
Sebastián Forero. GeoAI Solutions Engineer y fundador de GeoAI LATAM.
Para profundizar
- DINOv2 (Meta AI Research), paper y repositorio open source
- ArcGIS Pro 3.7, What's new: toolset Embeddings Based Analysis
- GeoAI toolbox, documentación de Esri
- Esri Developer Summit 2026, keynote sobre Geodemographic Embeddings.
#GeoAI #ArcGISPro #Embeddings #FoundationModels #DINOv2 #GeoAILATAM